
Enable asynchronous data loading & augmentation
PyTorch DataLoader supports asynchronous data loading/augmentation. The defaults settings are with 0 threads and no pinned memory. Use num_workers > 0 to enable asynchronous data processing, and it’s almost always better to use pinned memory.
Default settings:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)This is faster.
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=8, collate_fn=None,
pin_memory=True, drop_last=False, timeout=0,
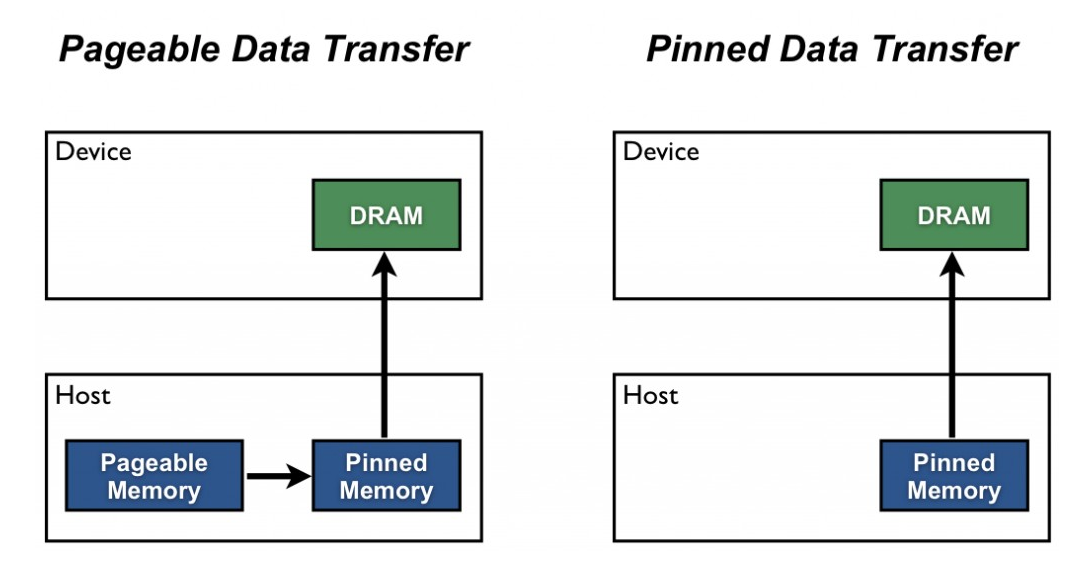
worker_init_fn=None)You know how sometimes your GPU memory shows that it’s full but you’re pretty sure that your model isn’t using that much? That overhead is called pinned memory. ie: this memory has been reserved as a type of “working allocation.” When you enable pinned_memory in a DataLoader it automatically puts the fetched data Tensors in pinned memory, and enables faster data transfer to CUDA-enabled GPUs.
Enable cuDNN autotuner
For convolutional neural networks, enable cuDNN autotuner by setting:
cuDNN supports many algorithms to compute convolution, and the autotuner runs a short benchmark and selects the algorithm with the best performance.
Increase batch size
Often AMP reduces memory requirements due to half float precision utilization. Thus increase the batch size to max out GPU memory.
When increasing batch size: * Tune the learning rate * Add learning rate warmup and learning rate decay * Tune weight decay or switch to optimizer designed for large-batch training * LARS * LAMB * NVLAMB * NovoGrad
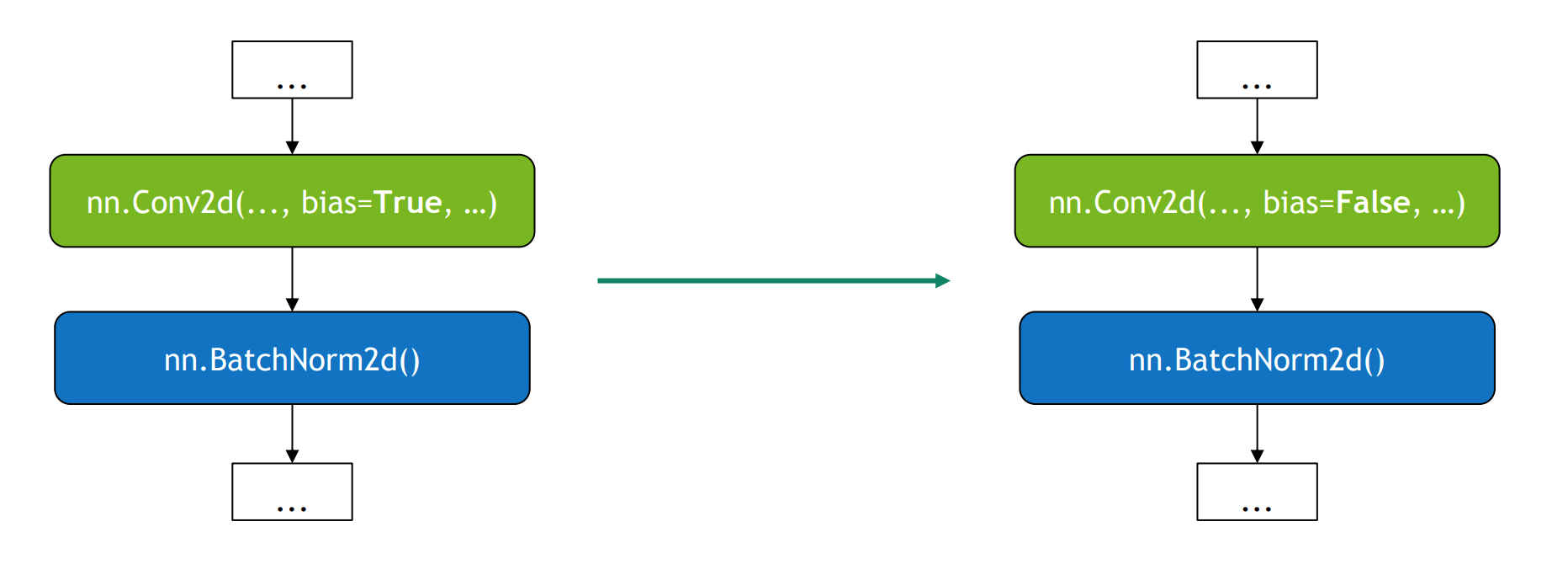
Disable bias for convolutions directly followed by a batch norm.
Use parameter.grad = None instead of model.zero_grad()
Not this:
But this!
The former executes memset for every parameter in the model, and backward pass updates gradients with “+=” operator (read + write). This is a slow and naive implementation of PyTorch, will hopefully be fixed. The latter doesn’t execute memset for every parameter, memory is zeroed-out by the allocator in a more efficient way and backward pass updates gradients with “=” operator (write).
Disable debug APIS for final training
There are many debug APIs that might be enabled, this slows everything down. Here are some: * torch.autograd.detect_anomaly * torch.autograd.set_detect_anomaly(True) * torch.autograd.profiler.profile * torch.autograd.profiler.emit_nvtx * torch.autograd.gradcheck * torch.autograd.gradgradcheck
Use efficient multi-GPU backend
DataParalell uses 1 CPU core and 1 python process to drives multiple GPUs. Works for a single node, but even for that DistributedDataparallel is often faster. IT provides 1 CPU core for each GPU, likewise 1 python process for each GPU. It can do Single-node and multi-node (same API), has efficient implementation with automatic bucketing for grad all-reduce, all-reduce overlapped with backward pass and is for all intended purposes multi-process programming.
Fuse pointwise operations
PyTorch JIT can fuse pointwise operations into a single CUDA kernel. Unfused pointwise operations are memory-bound, for each unfused op PyTorch has to: * launch a separate CUDA kernel * load data from global memory * perform computation * store results back into global memory
I.e from this:
to this:
Construct tensors directly on GPUs
Dont do this:
Instead, create the tensor directly on the device:
Its faster!
Summary:
- use async data loading / augmentation
- enable cuDNN autotuner
- increase the batch size, disable debug APIs and remove unnecessary computation
- efficiently zero-out gradients
- use DistributedDataParallel instead of DataParallel
- apply PyTorch JIT to fuse pointwise operations